Cloud 101 - Episode 3 : 7 clés pour éviter le gâchis !💰 #FinOps
Blague récurrente entre ingénieurs cloud : « ce qui coûte cher sur le cloud, ce n'est pas tant les ressources qu'on utilise que celles qu'on a oublié d'éteindre ». Lors d'une mission récente, cet adage s'est encore vérifié, puisque j'ai pu identifier en quelques heures plus de $20k d'économies mensuelles pour mon client (oui, parfois, on devrait négocier un intéressement).
Dans cet article, je vous partage quelques bonnes pratiques FinOps pour éviter le gâchis.
1. Une conscience partagée des coûts
Dans une infrastructure autogérée, l’essentiel des coûts est subi au moment de l’investissement (en général avec un coefficient de sécurité important), après quoi viennent les coûts humains (directs, ou via les contrats de support). On contrôle donc finement (parfois à l’excès) le temps passé sur chaque activité, et on ne regarde pas à la dépense concernant l’infra consommée (puisqu’elle est déjà payée).
Le modèle de paiement à l’usage du cloud implique que les décisions (ou non-décisions) sont toujours à venir : à chaque instant on peut redimensionner, supprimer, … et c’est d’autant plus important de le faire qu’ayant affaire à des services managés, le coût n’inclut pas seulement le matériel : on paie aussi à l’usage le service managé (gestion de l’infra physique, haute dispo, sauvegardes, patch management etc.).
Ici, LA bonne pratique : étiquetez 🏷️ vos ressources. Chaque ressource déployée doit être identifiée clairement par des tags qui permettront d’identifier dans les rapports le projet, l’équipe, le produit, la business unit, le processus métier, etc. qui justifie l’existence de la ressource.
Les tags doivent expliquer 100% de vos coûts, hors ressources non-étiquetables comme le trafic réseau (qui peut aussi faire l’objet d’analyses si besoin via les flow logs).
Il est possible de mettre en place des « politiques de tagging » pour garantir l’application de ces tags, soit ex-post par un audit soit ex-ante en refusant la création de ressources non-étiquetées.
2. Utilisez à fond les outils fournis par votre fournisseur
Rien que sur AWS, les outils sont nombreux :
- les Tags et Tag policies au niveau de l’organisation
- le Cost Explorer et les Cost & Usage Reports, tableaux croisés dynamiques qui permettent un reporting facile sur les coûts
- les recommandations de dimensionnement de Compute Optimizer et celles des Trusted Advisor pour les entreprises qui ont le niveau de support Business, qui permettent de ne pas sur-provisionner des ressources.
- la gestion des budgets, permettant de suivre les coûts par équipe
- la détection d’anomalie, au niveau de chaque compte, service ou étiquette
- les métriques de taux de couverture et d’utilisation des réservations de ressources.
Outre ces services disponibles sur étagère, il est possible, avec les Cloud Intelligence Dashboards, de déployer facilement de la BI avancée pour rendre actionnable l’information financière.
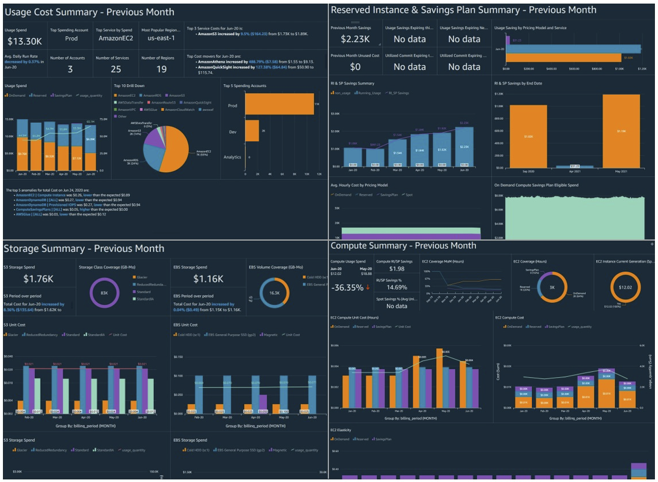
3. Définissez des politiques et automatisez
Le modèle de paiement à l’usage peut être mis à profit grâce aux possibilités d’automatisation du cloud (tout peut se contrôler via API).
Il est donc possible de déterminer des politiques qui seront effectivement mises en oeuvre sans effort après un petit investissement initial, par ex. « les ressources de test doivent être coupées entre 22h et 8h, à moins d’être taguées spécifiquement chaque semaine » sera automatisé par un processus quotidien d’extinction des ressources et un processus hebdo de suppression des étiquettes de rétention.
4. Prenez vos décisions de dimensionnement en s'appuyant sur des données
Sur le cloud, chaque service publie des métriques permettant d’avoir une compréhension précise de l’utilisation réelle des ressources.
Si le souhait d’assurer un démarrage sans accroc d’une nouvelle charge de travail peut amener à prendre un coefficient de sécurité important lors du pré-dimensionnement (mieux : on peut grâce à des services « serverless » s’épargner ce dimensionnement initial), ces métriques peuvent être exploitées après quelques semaines de vie de l’application pour « re-tailler » l’infrastructure au strict nécessaire.
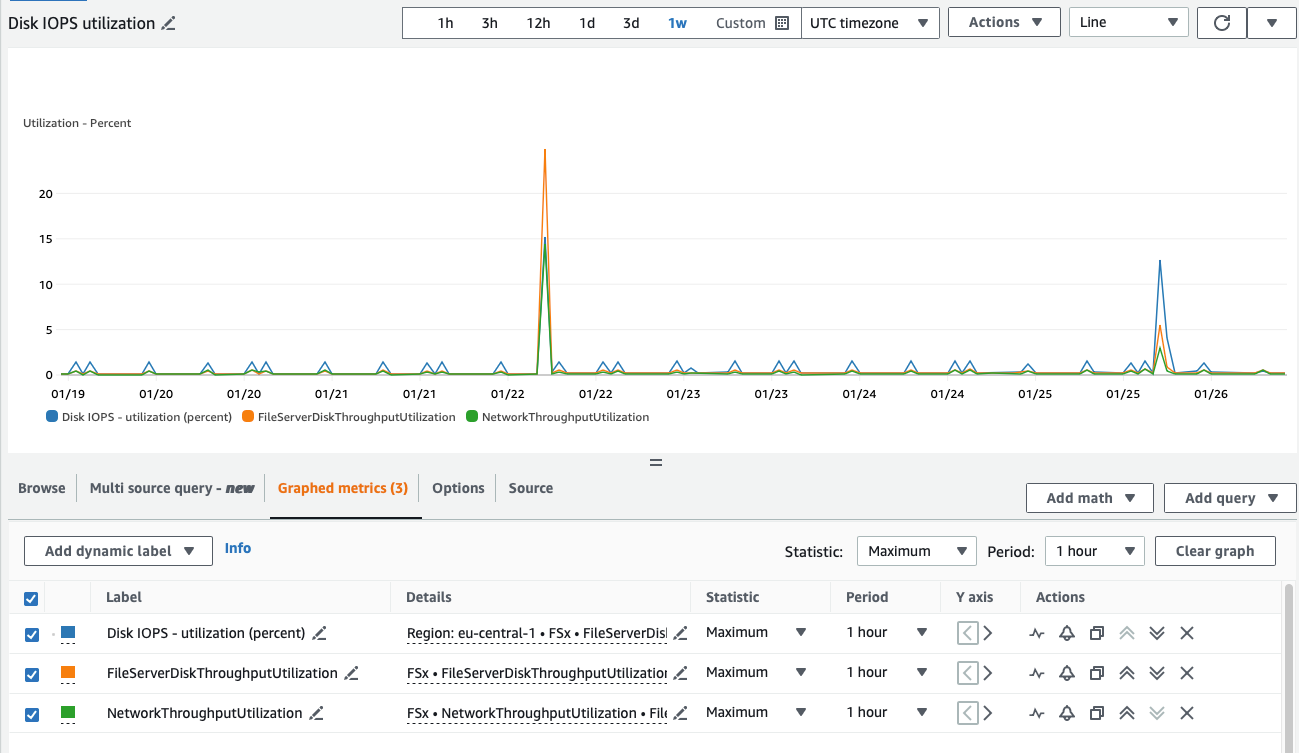
Notez que pour les machines virtuelles, seules les métriques d’hyperviseur (CPU, I/Os) sont activées par défaut (car l’hôte ne « sait pas » ce que la machine fait réellement de la mémoire ou de l’espace disque qui lui sont alloués). Sur AWS, il est donc souhaitable d’installer l’agent CloudWatch et de publier les métriques d’instances (RAM, Disk) qui sont alors prises en compte par Compute Optimizer pour fournir des recommandations pertinentes.
5. Une organisation adaptée au cloud
La caractéristique commune des organisations qui perdent inutilement de l’argent sur le cloud est que personne n’y est responsable des coûts. Il y a bien quelqu’un qui gère le budget annuel (souvent un manager), mais il n’est pas envisageable (ni souhaitable) qu’il soit associé à chaque choix de dimensionnement.
Ces décisions sont donc prises par les experts techniques : les DBA gèrent les bases de données, les SysOps gèrent les VMs, etc. et les décisions sont prises très loin des centres de profits.
Or, la principale source de valeur du cloud (cf. mon article à ce sujet) est la possibilité qu’il offre, en abaissant les barrières techniques, d’aligner business et technique. Et donc de constituer des équipes portant leur propre « P&L » (compte de résultat) d’infrastructure.
Dans ce modèle, le DBA est un spécialiste qui apporte un conseil, de l’analyse sur des problématiques difficiles, pas le type qui s’occupe de faire fonctionner les bases de données en boîte noire.
La formation est clé pour sensibiliser aux enjeux de coûts sur le cloud et orienter l’équipe vers la conception d’infrastructures pertinentes.
6. Des charges de travail adaptées au cloud
De plus, le fait d’être sur le cloud doit progressivement influer la conception même de vos applications, leur architecture, pour tirer le meilleur parti des services. Evitez d’être le prochain CTO qui fera un billet de blog « pourquoi j’ai quitté le cloud » (avec 🤦 garanti de tous les experts cloud qui au fil de sa lecture réalisent le désastre de mauvaise conception qui a mené à cette sortie).
Vos applications peuvent en particulier tirer parti en particulier de logiques de scalabilité horizontale (par autoscalingi.e. on ajoute et on retire des noeuds de calcul en fonction de la charge réelle) plutôt que verticale (on ajoute de la RAM, du CPU sur la/les machines qui portent l’application).
Elles peuvent aussi s’appuyer sur des services qui « scalent vers zéro »(pas d’usage, pas de coût) comme les Fonctions-as-a-Service (Lambda), les files ou bus d’événements managés (SQS, EventBridge) dont le modèle n’est plus un paiement à l’heure mais à l’appel (au million d’appel) d’API.
Plus proches de la prod (et plus conscientes des coûts), les équipes de développement auront à coeur de résoudre les problématiques de performance qui impactent significativement les coûts (par ex. cette requête SQL exécutée une fois par jour qui provoque le sur-dimensionnement de la BDD).
7. Des revues régulières
Chez mon client, la principale source de coûts non-justifiée résidait dans le volume d’instantanés (snapshots) conservés.
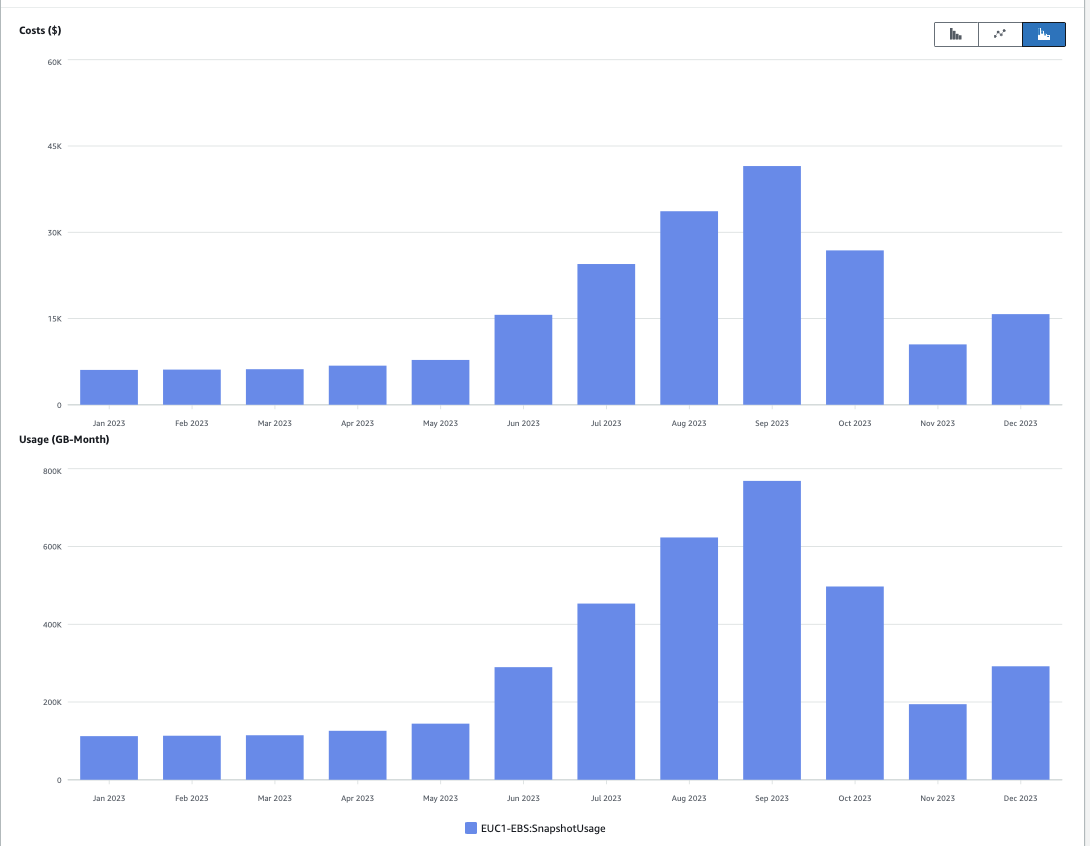
Une revue régulière aurait permis de questionner l’utilité de ces instantanés, et de définir le cas échéant le meilleur stockage pour ceux-ci (il y a un ratio de 53 entre Glacier Deep Archive – $0,00099 par Go.mois – et le stockage en ligne des instantanés – $0.053 par Go.mois).
A minima, une analyse « mois à mois » doit être menée sur les coûts pour identifier et expliquer les principales variations. Ce travail n’est pas nécessairement très important : il faut compter pour cela 2h de travail mensuel pour $5k/mois de coûts récurrents.
En complément, les Well Architected Framework Reviews sont l’occasion d’aborder cette question de l’optimisation des coûts, parmi d’autres (fiabilité, sécurité, etc.).
Un rôle d’animateur FinOps peut être identifié au sein de l’équipe pour faciliter l’animation de ces revues ; veillez cependant à ce que son existence ne soit pas déresponsabilisante pour le reste de l’équipe.
TerraCloud peut vous aider à progresser dans la maîtrise de votre infrastructure et de ses coûts, de l’analyse FinOps ponctuelle à la formation de vos équipes et l’accompagnement pour la mise en place de bonnes pratiques pérennes.